SOLUTIONS
インターネットは現在社会のインフラと言っても過言ではありません。しかし、そこで生産され続ける膨大な量のテキストは、特定のトピックに関する情報に限っても、個人がそのすべてを把握できるものではありません。また、個人や団体が公開するテキストは、ときに予想もしていなかった反応を引き起こします。
インターネットに振り回されるのではなく、情報を意思決定に利用できるか、正しく意思を伝えられるかは、社会的課題といえるでしょう。
京都テキストラボは、深層学習に金融工学や心理学を融合させ、テキスト情報のセンチメント分析から未来を予測するサービスと、そこから派生するサービスを個人や法人のお客様に提供し、インターネットの有効活用をサポートします。
また、テキスト深層学習技術を生かして、医療の分野などにおいて、テキスト情報の価値を最大限に引き出し、活用するシステムも開発しています。
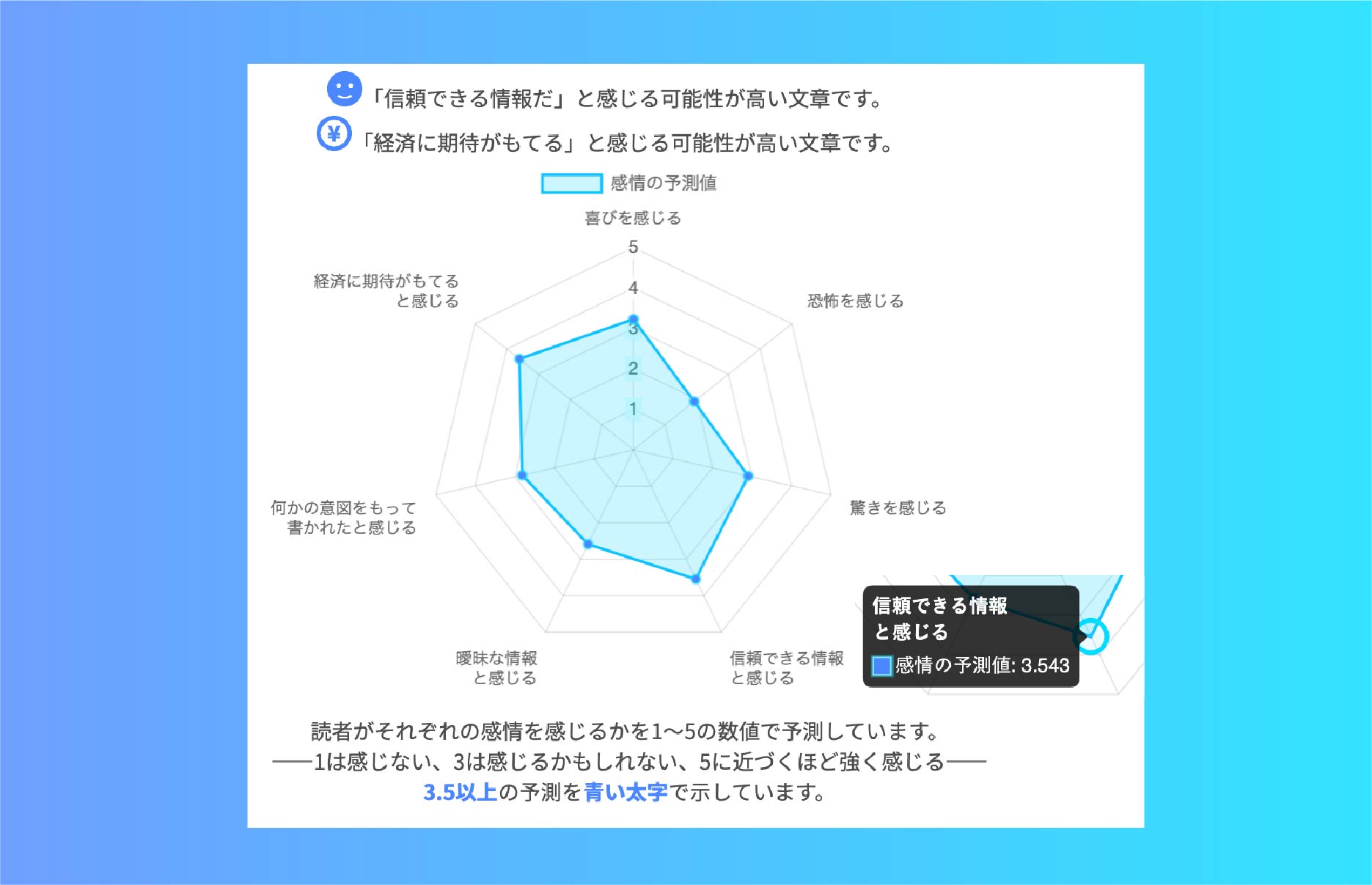
心理・感情の推定/予測サービス
京都テキストラボは深層学習を使ってテキスト情報を心理学的に分析するシステムの研究開発を行っています。たとえば、公開予定のテキストが思わぬ反応を引き起こすのを未然に防いだり、自己の心理状態を客観的に判断するのに役立てたり、不安を煽るコンテンツに迅速に対応したりといったことが可能になります。
2023年1月11日リリースの「 Text_Assist 」は、文章を読んだ人が抱く心理・感情を予測します。文章への反応を予測しながら推敲するのをサポートするツールとしてぜひご利用ください。[月額利用料 1000円]
Text_Assist フライヤ Text_Assist ガイド
Text_Assist ガイド 
金融取引の未来予測サービス
日経先物、TOPIX、マザーズ先物などの指数先物は、未来の変動を予測して売買するものです。現在の市場におけるセンチメント(心理)を観察することは、先物の価格を予測するために重要な要素といえるでしょう。
京都テキストラボは、深層学習を用いた、公開されている直近のテキスト情報のセンチメント分析から金融変動を予測するモデル「DLPredict」を2020年に開発し、予測精度を検証してきました。
このモデルでは、日経VI、日経先物、TOPIX、マザーズが「上がる」「下がる」「変動なし」のいずれであるかを予測します。ドル・円の為替、S&P(米国)の予測モデルも開発中です。
さらに、DLPredictを実際のトレーディングに活用するための技術「DL-RiskM」の開発を進めています。基本コンセプトは運用対象の分散、売買モデルの分散、適切なレバレッジ管理です。2023年7月より実証フェーズを開始します。


電子カルテの自動認識システム
電子カルテは効率的なデータ管理・共有に欠かせませんが、操作性を高めながら活用の幅を広げることが求められています。
操作性については、音声認識による入力システムが整備されつつあります。自動要約ができれば、医師や看護師の負担がさらに軽減されます。
また、電子カルテの利用価値を高めると期待されるのが、自動オーダリングシステムです。検査や処方の指示(オーダー)をより効率的に出せるようになります。
京都テキストラボは、音声認識によりテキスト化された情報を深層学習により自動認識し、要約やオーダリング情報(処方、検査、バイタルなど)を自動生成するプロジェクトを推進しています。
深層学習のキャリアアップ講座
近年、データサイエンスやAIを使った技術開発に対する社会的な期待と需要が高まっています。その高いニーズに対して、技術者は不足しています。京都テキストラボは、こういった分野の知識と技術が習得できるプログラムを構築しました。
AIのなかでも発展が目覚ましい深層学習は、これからのデータサイエンスにおける必須ツールです。私たちが提供するプログラムでは、Pythonによるプログラミングを学び、深層学習の基礎から始めて、最先端のツールであるPyTorch、BERTを使った実践的なテキスト分析に取り組みます。また、金融工学や心理学の内容もプログラムに取り入れています。
講師陣は、大学・企業で活躍するエキスパート。参加者とのQ&A、コミュニケーションを重視しながら講義と演習は進みます。リアルタイムの講義を受講できるだけでなく、録画をいつでも好きなときに復習に利用できます。
キャリアアップを目指す社会人、データサイエンスに興味のある学生の皆様のご参加をお待ちしています。AIの未経験者も大歓迎です。
講座概要PDF(随時実施)
ACCESS
シェアオフィス&ハウスEVER
電話が繋がりにくい場合は、
メールでご連絡いただければ幸いです。